Fachwissen für den Mittelstand
Der VBU Blog
Lernen Sie unsere Experten und Autoren kennen. Fachwissen für den Mittelstand.Was ist die Technologie hinter ChatGPT?

Die Veröffentlichung von ChatGPT durch OpenAI im Dezember 2022 hat viel Aufmerksamkeit erregt. Diese Neugier erstreckt sich von künstlicher Intelligenz im Allgemeinen, bis hin zu der Klasse von Technologien, die dem KI-Chatbot ChatGPT im Besonderen zugrunde liegen. Diese Modelle, die als Large Language Models (LLMs) bezeichnet werden, sind in der Lage, Antworten zu einer scheinbar endlosen Palette von Themen zu generieren. Das Verständnis von LLMs ist der Schlüssel zum Verständnis der Funktionsweise von ChatGPT. Was LLMs beeindruckend macht, ist ihre Fähigkeit, menschenähnlichen Text in vielen Sprachen, einschließlich Programmiersprachen, zu generieren. Diese Modellansätze sind echte technische Neuerungen und eröffnen neue Räume für weitere Innovationen.
In diesem Artikel wird erläutert, was diese Modelle sind, wie sie entwickelt werden, wie sie funktionieren und welche Möglichkeiten und Grenzen sich daraus ergeben. Die hier vorgestellten Informationen zu ChatGPT beziehen sich auf das zugrundeliegende GPT-3 Modell.
ChatGPT basiert auf einem neuralen Netzwerk
Ein neuronales Netzwerk ist eine Art maschinelles Lernmodell, das auf einer Reihe mathematischer Funktionen basiert, die ähnlich wie menschliche Nervenzellen – auch Neuronen genannt – vernetzt werden. Wie die Neuronen in einem menschlichen Gehirn, sind die künstlichen Neuronen das Grundelement der Informationsverarbeitung.
Jedes künstliche Neuron ist eine einfache mathematische Funktion, die eine Ausgabe basierend auf einer Eingabe berechnet. Die besonderen Fähigkeiten eines neuronalen Netzwerks kommen von der Verknüpfung der Neuronen untereinander.

Jedes künstliche Neuron ist mit einigen seiner Kollegen verbunden, und die Stärke jeder Verbindung wird durch eine numerische Gewichtung quantifiziert. Sie bestimmen, inwieweit die Ausgabe eines Neurons als Eingabe für ein nachfolgendes Neuron berücksichtigt wird.
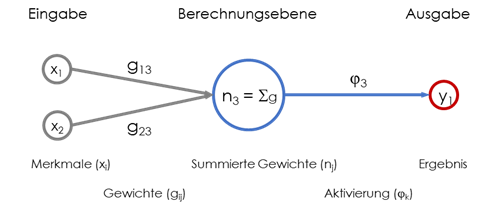
Ein neuronales Netzwerk kann sehr klein sein. Zum Beispiel kann ein Neuron mit nur fünf Folgeneuronen über fünf Verbindungen verknüpft sein. Ein neuronales Netz kann aber auch sehr groß sein, wie es bei den LLMs der Fall ist. Diese können Millionen von Neuronen mit vielen hundert Milliarden Verbindungen zwischen ihnen ausweisen, wobei jede Verbindung ihre eigene Gewichtung hat.
ChatGPT verwendet eine Transformer-Architektur
Wir wissen bereits, dass ein Large Language Modell (LLM) eine Art neuronales Netzwerk ist. Genauer gesagt, verwenden LLMs eine bestimmte neuronale Netzwerkarchitektur, die als Transformator bezeichnet wird und dazu dient, Daten wie Text nacheinander zu verarbeiten und zu generieren.
Eine Architektur beschreibt in diesem Zusammenhang, wie die Neuronen miteinander verbunden sind. Alle neuronalen Netze gruppieren ihre Neuronen in eine Reihe verschiedener Schichten. Wenn es viele Schichten gibt, wird das Netzwerk als "tief" (engl. "deep") bezeichnet, daher der Begriff "Deep Learning". In einer sehr einfachen neuronalen Netzwerkarchitektur kann jedes Neuron mit jedem Neuron in der benachbarten Schicht verbunden sein. In anderen Fällen kann ein Neuron nur mit einigen anderen Neuronen verbunden sein, die sich in Rasternähe befinden.
Letzteres ist bei sogenannten Convolutional Neural Networks (CNN) der Fall. CNNs haben in den letzten zehn Jahren enorme Fortschritte in der modernen Bilderkennung erzielt. Die Tatsache, dass das CNN in einem Raster strukturiert ist, wie das Pixelraster in einem Bild, ist kein Zufall – in der Tat ist es ein cleverer Ansatz, bei dem sich herausgestellt hat, dass er für Bilddaten ausgezeichnet funktioniert.
![]()
Der für Texte verwendete „Transformer“ ist jedoch etwas anders. Ein Transformer, der 2017 von Forschern bei Google entwickelt wurde, führt die Idee der „Attention“ (dt. „Aufmerksamkeit“) ein. Hierbei werden bestimmte Neuronen stärker mit anderen Neuronen verbunden, das heißt, ihnen wird mehr Aufmerksamkeit geschenkt.
Da Text zur digitalen Verarbeitung sequenziell ein- und ausgelesen wird, also ein Wort nach dem anderen, aber unsere Sprache Sätze nutzt, in denen verschiedene Satzteile auf andere verweisen oder diese inhaltlich modifizieren, z. B. „Paul, der einen Hund hat, lebt in Hamburg“, ist eine Verknüpfung der Worte und Satzteile hilfreich, um den Sinninhalt zu erhalten.
![]()
So ist es kein Zufall, dass eine Architektur, die zwar so aufgebaut ist, dass sie sequenziell abarbeitet, aber mit unterschiedlichen Gewichten die Beziehungen zwischen verschiedenen Worten einbezieht, bei textbasierten Daten bessere Ergebnisse liefert.
ChatGPT lernt selbständig
Einfach ausgedrückt, ist ein Modell ein Computerprogramm. Es handelt sich um eine Reihe von Anweisungen, die verschiedene Berechnungen für ihre Eingabedaten durchführen und eine Ausgabe berechnen. Das Besondere an einem Modell für maschinelles Lernen oder KI ist jedoch, dass die menschlichen Programmierer diese Anweisungen nicht explizit schreiben, sondern eine Reihe von Anweisungen in Form eines Algorithmus schreiben, der dann große Mengen vorhandener Daten überprüft, um das Modell selbst zu erzeugen.
Daher erstellen die menschlichen Programmierer nicht das Modell, sondern den Algorithmus, und der Algorithmus erstellt dann das Modell. Im Falle eines LLMs bedeutet dies, dass die Programmierer die Architektur für das Modell und die Regeln definieren, nach denen es erstellt wird. Aber sie erzeugen nicht die künstlichen Neuronen oder die Gewichte zwischen den künstlichen Neuronen. Dies geschieht in einem Prozess, der als "Training" bezeichnet wird, bei dem das Modell gemäß den Anweisungen des Algorithmus seine Variablen selbst definiert.

Im Falle eines LLMs handelt es sich bei den überprüften Daten um Text. In einigen Fällen kann es spezialisierter oder allgemeiner sein. In den größten Modellen besteht das Ziel darin, dem Modell so viel grammatikalischen Text wie möglich zur Verfügung zu stellen, aus dem es lernen kann. Während des Trainingsprozesses, der im Beispiel von ChatGPT Cloud-Computing-Ressourcen im Wert von vielen Millionen Dollar verbrauchen kann, überprüft das Modell diesen Text und versucht, einen eigenen Text zu erstellen. Anfangs ist die Ausgabe noch Kauderwelsch, aber durch einen umfangreichen Prozess von Versuch-und-Irrtum – und durch den kontinuierlichen Vergleich der Ausgabe mit der Eingabe – verbessert sich die Qualität der Ausgabe allmählich. Der Text wird verständlicher. Mit genügend Zeit, genügend Rechenressourcen und genügend Trainingsdaten "lernt" das Modell, einen Text zu erzeugen, der für den menschlichen Leser nicht von einem durch Menschen geschriebenen Text zu unterscheiden ist.

ChatGPT verwendet die Technik des verstärkten Lernens durch menschliches Feedback (Reinforcement Learning from Human Feedback, RLHF). Die Idee besteht darin, Menschen mehrere automatisch generierte Antworten anzubieten, die diese von der besten bis zur schlechtesten Antwort priorisieren. Anschließend wird ein Algorithmus darauf trainiert, die Antworten vorherzusagen, die für einen Menschen am überzeugendsten sind. Das Modell berücksichtigt dies und passt sich auf der Grundlage dieses Feedbacks kontinuierlich an.
ChatGPT sagt voraus, welches Wort dem vorherigen folgen soll
Eine vereinfachte Beschreibung von LLMs ist, dass sie "einfach das nächste Wort in einer Sequenz vorhersagen". Das stimmt, aber es ignoriert die Tatsache, dass dieser einfache Prozess dazu führen kann, dass Werkzeuge wie ChatGPT bemerkenswert hochwertigen Text generieren. Es ist genauso einfach zu sagen, dass "ein Modell einfach nur mathematische Rechnungen durchführt", was zwar korrekt ist, aber nicht sehr hilfreich, um zu verstehen, welche Potentiale oder Leistungsfähigkeiten ein Modell besitzt.
Das Ergebnis des oben beschriebenen Trainingsprozesses ist ein künstliches neuronales Netzwerk mit Hunderten von Milliarden von Verbindungen zwischen den Millionen von Neuronen, die jeweils durch das Modell selbst definiert werden. Die größten Modelle repräsentieren ein riesiges Datenvolumen, vielleicht mehrere hundert Gigabyte, nur um alle Gewichtungen zu speichern.
Jedes der Gewichtungen und jedes der Neuronen ist eine mathematische Formel, die für jedes Wort, oder in einigen Fällen einen Teil eines Wortes, berechnet werden muss, das dem Modell für seine Eingabe zur Verfügung gestellt wird, und für jedes Wort, oder einen Teil eines Wortes, das es als Ausgabe generiert. Technisch werden diese "kleinen Wörter oder Wortteile" als "Token" bezeichnet, und bilden bei einigen Anbietern auch die Berechnungsgrundlage für die anfallende Kosten zur Bereitstellung solcher Technologien.
Ein Benutzer, der mit einem dieser Sprachmodelle interagiert, liefert eine Eingabe in Form von Text. Die Modelle hinter ChatGPT teilen diese Eingabeaufforderung in Tokens (Wörter oder Wortteile) auf. Das GPT-3-Modell, auf dem das gpt-3.5-turbo-Modell basiert, hat 175 Milliarden Gewichte, was bedeutet, dass ein Satz mit 20 Worten etwa 20 Tokens erzeugt und zu 20 × 175 Milliarden = 3,5 Billionen Berechnungen führen würden. Daraus würde das Modell eine Antwort generieren, die basierend auf der immensen Textmenge, die es während des Trainings verbraucht hat, richtig klingt.
Wichtig ist, dass es nicht die Antwort nachschlägt. Es hat keinen Speicher, in dem es nach relevanten Begriffen suchen kann. Stattdessen macht es sich daran, jedes Token des Ausgabetextes zu generieren, führt die 175 Milliarden Berechnungen erneut durch und generiert ein Token (Wort oder Wortteil), das die höchste Wahrscheinlichkeit hat, richtig zu klingen.
ChatGPT produziert Text, der richtig klingt, aber nicht unbedingt richtig ist
LLMs wie ChatGPT können keine Garantie dafür geben, dass ihre Antwort richtig ist, sondern nur, dass sie richtig klingt. Seine Antworten werden nicht in seinem Gedächtnis nachgeschlagen - sie werden im Handumdrehen auf der Grundlage der zuvor beschriebenen 175 Milliarden Gewichte generiert. Dies ist kein spezifisches Manko von ChatGPT, sondern der aktuelle Ansatz aller LLMs. Ihre Fähigkeit besteht nicht darin, sich an Fakten zu erinnern – das machen schon die einfachsten Datenbanken perfekt. Ihre Stärke liegt vielmehr darin, Text zu generieren, der sich wie von Menschen geschriebener Text liest und der korrekt klingt. In vielen Fällen wird der Text, der korrekt klingt, auch richtig sein, aber eben nicht immer. Besonders deutlich wird es, wenn nach Rechenaufgaben gefragt wird, denn Textverständnis unterscheidet sich deutlich von den strengen mathematischen Regeln, die ChatGPT nur begrenzt vorliegen, z.B. liefert ChatGPT auf die Frage „Was ist 777 × 111?“ die Antwort „777 × 111 = 86.187“, das korrekte Ergebnis wäre 86.247 gewesen.

In Zukunft ist es wahrscheinlich, dass LLMs in weitere Systeme integriert werden, die die Leistungsfähigkeit der LLM-Textgenerierung mit der von kalkulatorischen Lösungen oder Wissensdatenbanken kombinieren, um sachlich korrekte Antworten in überzeugenden Texten in natürlicher Sprache zu liefern. Diese Systeme existieren heute noch nicht, erscheinen aber im Rahmen des Möglichen.
Ist auch das neue GPT-4 ein LLM?
Am 14. März 2023 veröffentlichte OpenAI den Nachfolger GPT-4, die neueste Version seiner Modelle in der GPT-Familie. GPT-4 generiert nicht nur qualitativ hochwertigeren Text im Vergleich zu GPT-3.5, sondern bietet auch die Möglichkeit, Bilder zu erkennen. [1]

Prüfungsergebnisse: GPT-Leistung bei akademischen und beruflichen Prüfungen. In jedem Fall wurden die Bedingungen und die Bewertung der realen Prüfung simuliert. Die Prüfungsergebnisse sind, basierend auf der GPT-3.5-Leistung, von niedrig bis hoch sortiert. GPT-4 übertrifft GPT-3.5 bei den meisten getesteten Prüfungen. Um eine konservative Bewertung zu liefern, sind nur die unteren Enden der Perzentil-Bereiche angegeben. Dies führt zu einigen Artefakten bei den AP-Prüfungen, die eine breite Bewertungsspreizung aufweisen. Obwohl GPT-4 beispielsweise die höchstmögliche Punktzahl in AP Biology von „5 aus 5“ erreicht, wird dies in der Grafik als 85. Perzentil angezeigt, da 15 Prozent der Testteilnehmer diese Punktzahl erreichten. [1]
Die Fähigkeit, Eingabe- und Ausgabedaten verschiedener Typen (Text, Bilder, Video, Audio usw.) zu verarbeiten, bedeutet, dass GPT-4 bereits multimodal ist, das heißt, verschiedene KI-Ansätze vereinigt und einer allgemeinen künstlichen Intelligenz näherkommt.
Fazit
Die Entwicklungen der Technologien für künstlicher Intelligenz schreiten rasend voran. Mit ChatGPT wurde ein Chat Bot veröffentlicht, der den berühmten Turing-Test [2] glaubhaft absolviert, und damit seine Antworten nur noch schwer von denen eines Menschen zu unterscheiden sind.
Technisch basiert ChatGPT auf einem Large Language Model des Typs GPT-3.5, das heißt, es
- basiert auf einem neuralen Netzwerk, das mithilfe enormer Rechenleistung und Datenmengen erzeugt wurde
- verwendet eine auf Text abgestimmte Transformer-Architektur, die Text in Zahlen und wieder in Text umwandelt, und sich immer noch mit Humor und Ironie schwertut
- lernt selbständig und mithilfe von Menschen, um eine sowohl sachlich als auch politisch korrekte Antwort zu erzeugen
- sagt voraus, welches Wort dem vorherigen folgen soll, was in der deutschen Sprache mit seinen vorkommenden Schachtelsätzen nicht immer gelingt
- produziert Text, der richtig klingt, aber nicht unbedingt sachlich richtig ist
- tut sich als textbasiertes Sprachmodell mit dem Rechnen schwer
Mit dem Nachfolger GPT-4 beherrscht ChatGPT neben Text nun auch Bild, Ton und Video und bildet damit die nächste Stufe auf dem Weg zur künstlichen Intelligenz.
Quellen
[1] GPT-4 Technical Report, Open AI, March 2023.
[2] Turing-Test, Wikipedia, März 2023.
Autor
Dr. Markus Skipinski ist seit 2018 selbständiger Berater für strategische und prozessorientierte Innovation und Experte für Business Intelligence (biz-innovation.de). Er besitzt eine 20-jährige Berufserfahrung in verschiedenen Branchen darunter Chemische Industrie, Automobilindustrie und Waschmittelindustrie. Seine Beratungsschwerpunkte sind die Entwicklung von Innovationsstrategien, die Einführung und Optimierung von Innovationsprozessen und die Förderung der Innovationskultur, sowie die Einführung digitaler Verfahren zur Entscheidungsunterstützung mittels Business Intelligence und maschinellem Lernen.
Beitragsbild: Bild von Alexandra_Koch auf Pixabay
Wenn Sie den Blog abonnieren, senden wir Ihnen eine E-Mail, wenn es neue Updates auf der Website gibt, damit Sie sie nicht verpassen.
Über den Autor
Kontakt
Verbund beratender Unternehmer e.V.
Adenauerallee 12-14
53113 Bonn
Telefon: +49 228 966985-19
E-Mail: vorstand@vbu-berater.de
Kommentare